Study Results
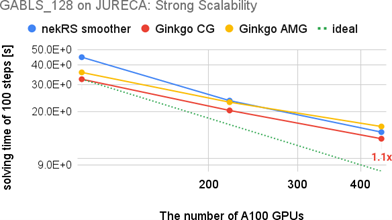
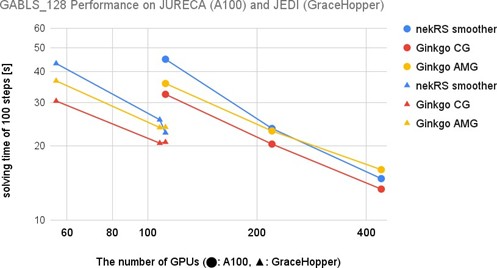
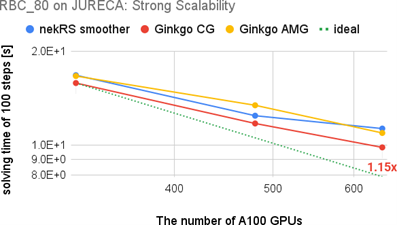
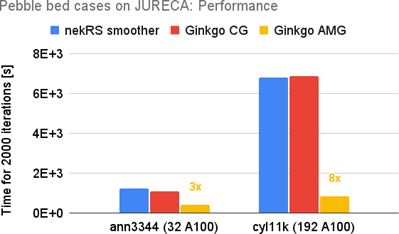
We have extended the underlying solver support of nekRS by successfully adding Ginkgo as another linear solver backend. We have simulated the application from the perspective of different cases: 1. A GABLS – GEWEX Atmospheric Boundary Layer Study, 2. RBC – Rayleigh-Bénard convection 3. Pebble bed cases, with nekRS and Ginkgo’s linear solver on different supercomputers like Jureca and Jedi (prototypes of Jupyter) from JSC for NVIDIA GPUs. We have shown that mixed-precision technology can improve performance without decreasing precision, even in a distributed environment like the GABLS problem. For challenging problems like pebble bed cases, Ginkgo’s AMG method shows promising convergence improvement such that nekRS with Ginkgo’s AMG method outperforms the one using the native nekRS smoother by up to 8x. A resulting scientific paper demonstrating the performance benefits is included in the proceedings of ParCFD.
NekRS https://github.com/Nek5000/nekRS is a CFD solver based on libparanumal and Nek5000. Numerically, it relies on the spectral element method, which makes it well suited for the efficient simulation of turbulence, where the number of grid points grows faster than quadratically with the Reynolds number when all flow features must be resolved.
Ginkgo https://ginkgo-project.github.io is a software library focusing on efficiently handling sparse linear systems on GPUs. The software features multiple backends in hardware-native languages. Ginkgo contains a set of iterative solvers, including Krylov solvers, algebraic multigrid (AMG), and parallel preconditioners like incomplete LU that serve as a valuable sparse linear algebra backend for application codes.
Benefits
- We demonstrated how to integrate the Ginkgo math library with the nekRS simulation framework as an optional backend. This same experience and techniques could be applied to another application that can benefit from Ginkgo’s performance portability.
- The Ginkgo backend brings a plethora of numerical methods to NekRS such that application engineers can choose from a wide range of solvers and preconditioners when tuning the performance of their test cases. This reduces runtime and resource consumption of nekRS production runs for industry and research.
- During this experiment, we deployed a low-communication mixed precision AMG method with Ginkgo that improves the performance of nekRS when tackling hard problems. This reduces runtime and resource consumption of nekRS production runs for industry and research.
- We demonstrated that the Ginkgo software stack itself and its integration with nekRS are Exascale-ready in terms of weak and strong scalability on the Grace-Hopper hardware on which Europe’s first Exascale system will be built.
Partners
| The Juelich Supercomputing Centre (JSC) is the first institution in Europe to deploy and operate an Exascale-level supercomputer: the NVIDIA Grace-Hopper powered supercomputer Jupyter. While Jupyter is expected to be operational by the end of 2025, JSC already hosted a Grace-Hopper system, Jedi, during the inno4scale project timeline that serves as the development and testing platform for preparing algorithms and software for the Jupiter system. JSC has extensive expertise in high performance computing and is an active developer and user of the nekRS high performance Computational Fluid Dynamics (CFD) code. For the AceAMG experiment, JSC provides the expertise and experience in developing, integrating and running nekRS on HPC systems, as well as relevant test cases that stress the capability and performance of the numerical methods. |
| The Computational Mathematics (CoMa) research group of Prof. Dr. Hartwig Anzt (initially located at the Karlsruhe Institute of Technology at the time of experiment acceptance and subsequently at the Technical University of Munich during experiment execution) focuses on the development and production-ready implementation of numerical methods for high performance computing on GPU-centric systems. Methods suitable for these hardware configuration levels combine fine-grained parallelism with low communication and synchronization requirements, and typically employ low precision formats for part of the computations. For the AceAMG experiment, the CoMa research group contributes the expertise necessary for designing and implementing a low-communication mixed precision distributed Algebraic Multigrid (AMG) method, and integrating this functionality as a high-performance linear solver in the nekRS simulation framework. |
Team
- Prof. Hartwig Anzt
- Dr. Mathis Bode
- Dr. Andreas Herten
- Dr. Yu-Hsiang Tsai
- Dr. Gregor Olenik
- Dr. Jens Henrik Göbbert
Contact
Name: Hartwig Anzt
Institution: Technical University of Munich
Email Address: hartwig.anzt@tum.de